近日,在國際頂級圖學(xué)習(xí)標(biāo)準(zhǔn)OGB(Open Graph Benchmark)挑戰(zhàn)賽中,第四范式憑借AutoML(自動機(jī)器學(xué)習(xí))技術(shù),在與斯坦福大學(xué)、康奈爾大學(xué)、Facebook、阿里巴巴等國際頂尖高校與科技巨頭同場競技中脫穎而出,以較大優(yōu)勢斬獲ogbl-biokg、ogbl-wikikg2兩項任務(wù)榜單第一。
近年來,知識圖譜因可挖掘?qū)嶓w之間的潛在關(guān)系、提供更高效的搜索結(jié)果,被廣泛應(yīng)用在智能搜索、智能問答、社交網(wǎng)絡(luò)、金融風(fēng)控等諸多行業(yè)應(yīng)用中。作為知識圖譜領(lǐng)域重要的技術(shù)手段,圖學(xué)習(xí)已成為機(jī)器學(xué)習(xí)重要的研究領(lǐng)域之一,受到了學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注。
OGB是目前公認(rèn)的圖學(xué)習(xí)基準(zhǔn)數(shù)據(jù)集代表,由斯坦福大學(xué)Jure Leskovec教授團(tuán)隊建立,于2019年國際頂級學(xué)術(shù)會議NeurIPS上正式開源。其囊括了節(jié)點性質(zhì)預(yù)測、邊性質(zhì)鏈接預(yù)測、圖性質(zhì)預(yù)測等知識圖譜領(lǐng)域眾多權(quán)威賽題,以質(zhì)量高、規(guī)模大、場景復(fù)雜、難度高著稱,素有知識圖譜領(lǐng)域“ImageNet”之稱,成為眾多科技巨頭、科研院所和高校團(tuán)隊試驗技術(shù)成色的試金石。
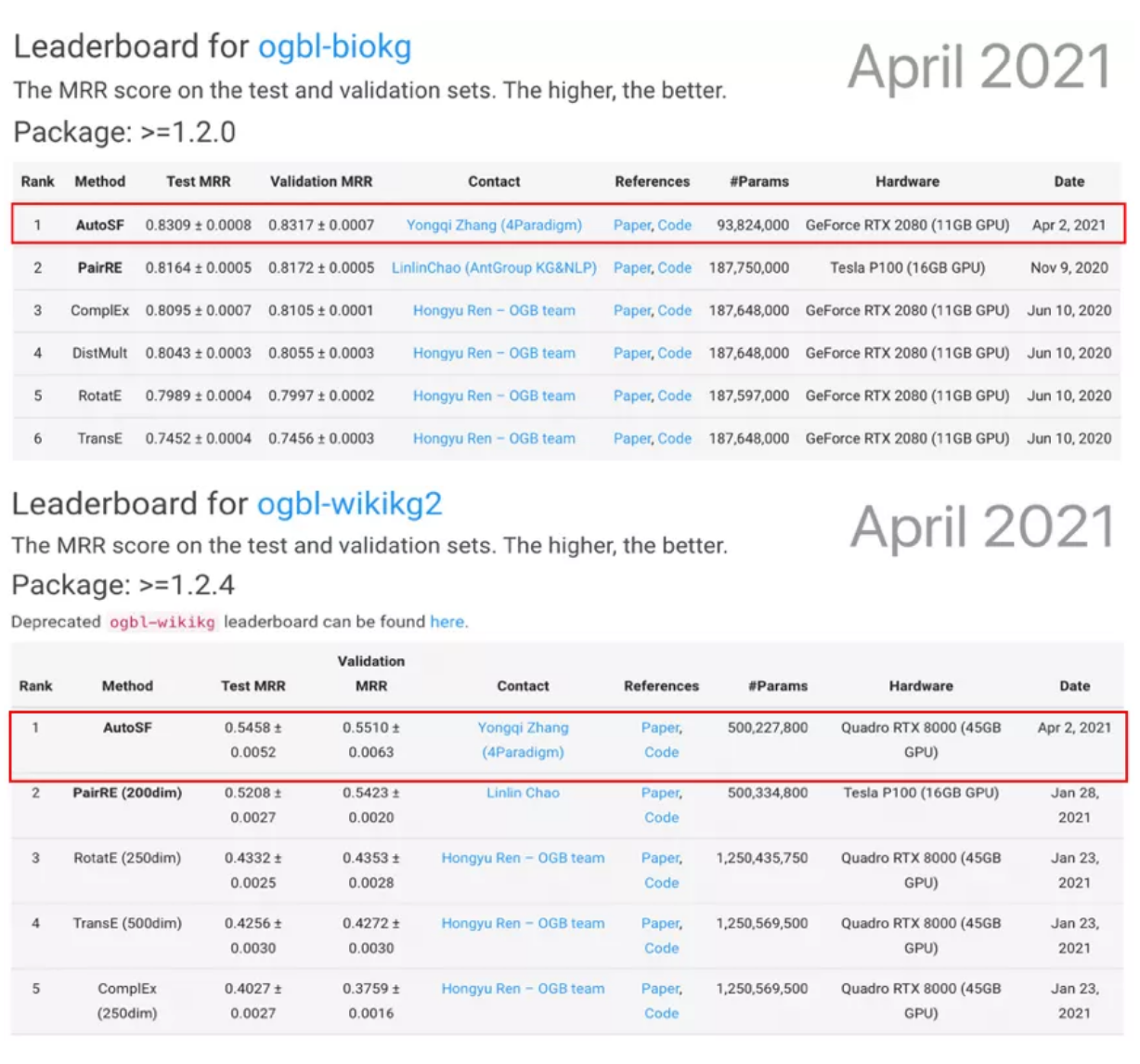
此次,第四范式參與了ogbl-biokg、ogbl-wikikg2兩項數(shù)據(jù)量龐大且極具業(yè)務(wù)價值的知識圖譜鏈接預(yù)測任務(wù),均在處理嘈雜、不完整知識圖譜等方面挑戰(zhàn)巨大。其中,ogbl-biokg包含多個海量生物醫(yī)學(xué)知識庫,構(gòu)成了500多萬個三元組(實體-關(guān)系-實體、實體-屬性-屬性值),在藥物屬性預(yù)測及生物醫(yī)學(xué)研究方面具有重要意義。ogbl-wikikg2來源于Wikidata知識庫,需要在1700多萬個事實三元組中精準(zhǔn)預(yù)測實體間的潛在關(guān)系,可有效提升推薦系統(tǒng)、智能問答等場景應(yīng)用效果。
為了精準(zhǔn)理解數(shù)據(jù)集中復(fù)雜語義信息、挖掘潛在關(guān)系,業(yè)界通常以評分函數(shù)(SF)作為衡量知識圖譜中三元組可編程性的重要指標(biāo),但現(xiàn)有評分函數(shù)設(shè)計僅專注于某一類語義模型,無法應(yīng)對實際應(yīng)用中千變?nèi)f化的知識圖譜任務(wù)場景。
受AutoML啟發(fā),第四范式本次采用AutoSF(自動評分函數(shù))參賽,通過理解生物醫(yī)學(xué)、維基百科等復(fù)雜知識圖譜中的不同語義信息,設(shè)計出更符合場景認(rèn)知特性的評分函數(shù),實現(xiàn)在對應(yīng)任務(wù)上的性能突破。同時,AutoSF設(shè)計的評分函數(shù)可高效利用模型參數(shù),在具有更小模型復(fù)雜度的基礎(chǔ)上,預(yù)測性能位居第一,以較大優(yōu)勢超過PairRE、TransE、ComplEx、RotatE等其他知名評分函數(shù)。

