推理性能提升10倍,成本下降一半!第四范式發布大模型推理加速卡、推理框架
2024-03-18
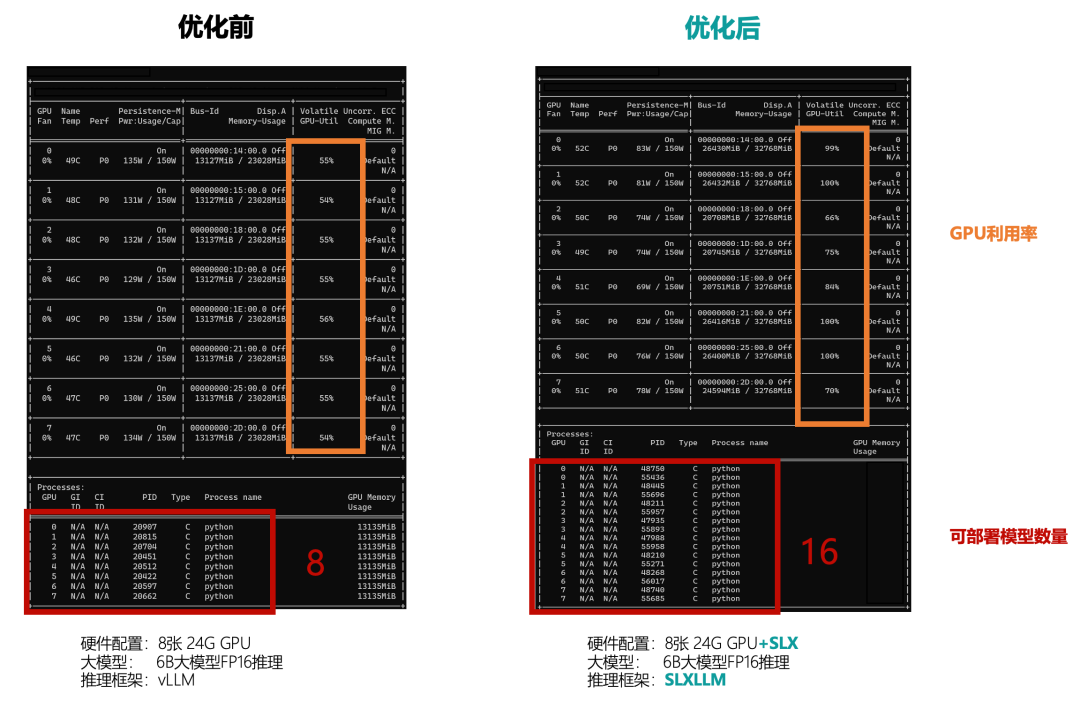

為此,第四范式發布了大模型推理框架SLXLLM以及推理加速卡SLX,在二者聯合優化下,在文本生成類場景中,大模型推理性能提升10倍。例如在使用4張80G GPU對72B大模型進行推理測試中,相較于使用vLLM,第四范式使用SLXLLM+SLX的方案,可同時運行任務數量從4增至40。此外,推理加速卡SLX也可兼容TGI、FastLLM、vLLM等主流大模型推理框架,大模型推理性能提升約1-8倍。
企業智能化轉型,第四范式助您一臂之力

